AI 순위가 뒤집혔다? DeepSWE로 본 AI 성능 순위와 코딩 에이전트 순위
AI 코딩 에이전트 순위표를 보면 한동안은 비슷한 숫자들이 나란히 붙어 있는 느낌이 강했습니다. 모델 이름만 바뀌고, 점수 차이는 작고, 실제 개발에서 “이게 하루짜리 일을 끝까지 밀고 가느냐”는 감각은 잘 보이지 않았습니다.
그런데 이번 DeepSWE 이미지는 조금 다르게 봐야 합니다. 단순히 “GPT-5.5가 70%로 1등”이라는 순위표가 아니라, 앞으로 코딩 AI를 평가할 때 기준이 어디로 옮겨가고 있는지를 보여주는 장면에 가깝습니다.
핵심 요약
- DeepSWE는 프런티어 코딩 에이전트를 장기 소프트웨어 엔지니어링 과제로 평가하는 벤치마크입니다.
- 공식 설명 기준 113개 과제, 91개 저장소, 5개 언어를 포함합니다.
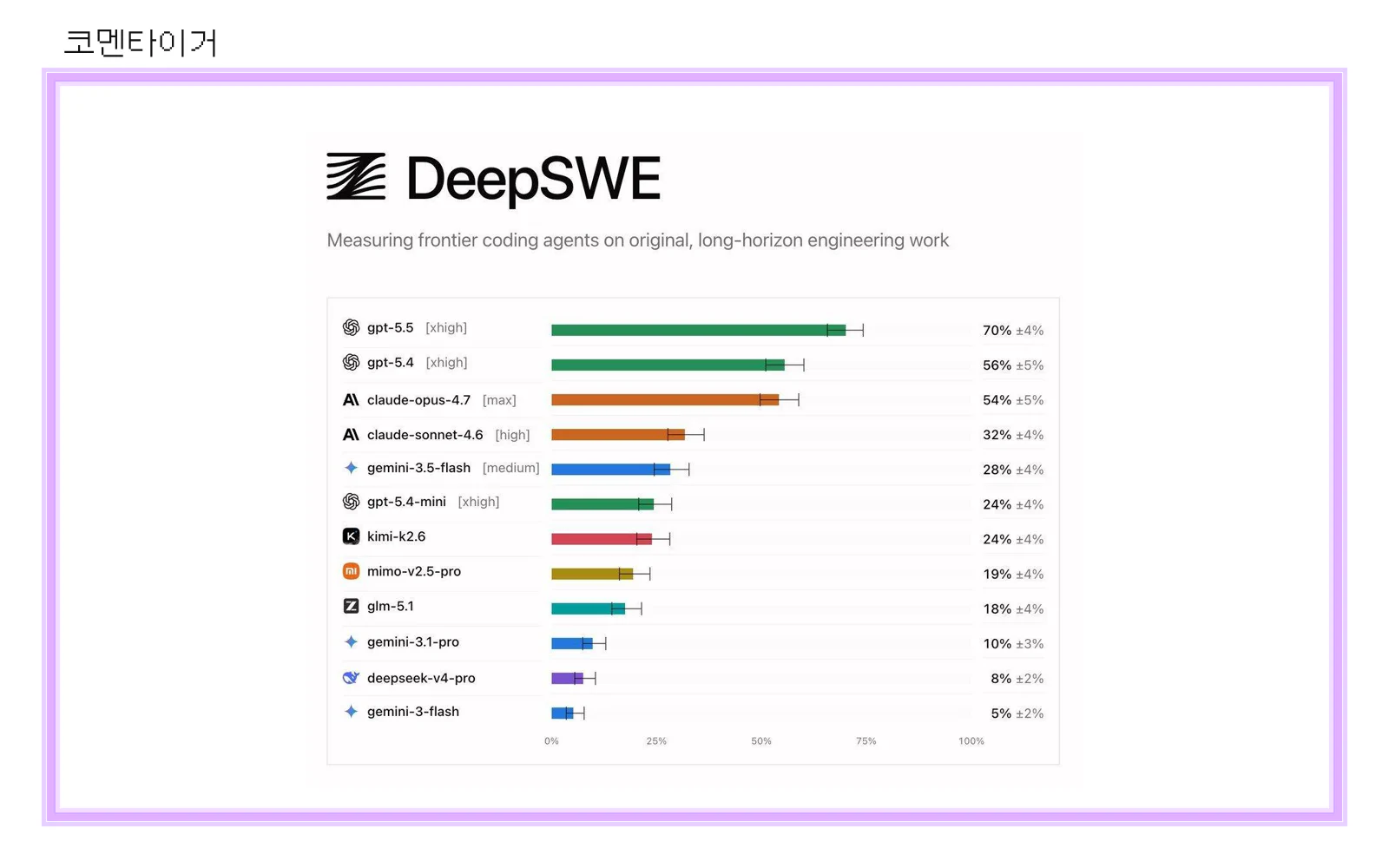
- 첨부 이미지 기준 GPT-5.5가 70% ±4%로 가장 높은 점수를 기록했습니다.
- GPT-5.4는 56% ±5%, Claude Opus 4.7은 54% ±5%로 뒤를 이었습니다.
- 이 벤치마크의 의미는 “코딩 문제를 맞히는 AI”보다 “실제 저장소에서 오래 걸리는 변경을 끝까지 처리하는 AI”를 보려는 데 있습니다.
DeepSWE란 무엇인가?
DeepSWE는 Datacurve가 공개한 코딩 에이전트 평가 벤치마크입니다. 공식 소개 문구는 “original, long-horizon software engineering tasks”, 즉 기존 문제를 그대로 가져온 짧은 코딩 문제가 아니라 새로 만든 장기 소프트웨어 엔지니어링 과제에 초점을 둔다고 설명합니다.
여기서 중요한 단어는 long-horizon입니다. 단일 함수 하나를 고치는 문제가 아니라, 실제 오픈소스 저장소를 읽고, 여러 파일을 바꾸고, 테스트를 통과시키고, 요구사항의 의도를 끝까지 맞춰야 하는 문제에 가깝다는 뜻입니다.
공식 README에 따르면 DeepSWE 과제는 TypeScript, Go, Python, JavaScript, Rust에 걸쳐 있으며, 각 과제는 격리된 환경과 프로그램 기반 검증기를 포함합니다. 단순 정답 문자열을 맞히는 방식이 아니라, 프롬프트가 요구한 동작이 실제로 구현됐는지를 검증하는 구조입니다.

이미지 속 순위는 어떻게 읽어야 하나?
첨부 이미지 기준 DeepSWE 리더보드는 다음 흐름을 보여줍니다.
- gpt-5.5: 70% ±4%
- gpt-5.4: 56% ±5%
- claude-opus-4.7: 54% ±5%
- claude-sonnet-4.6: 32% ±4%
- gemini-3.5-flash: 28% ±4%
- gpt-5.4-mini와 kimi-k2.6: 각각 24% ±4%
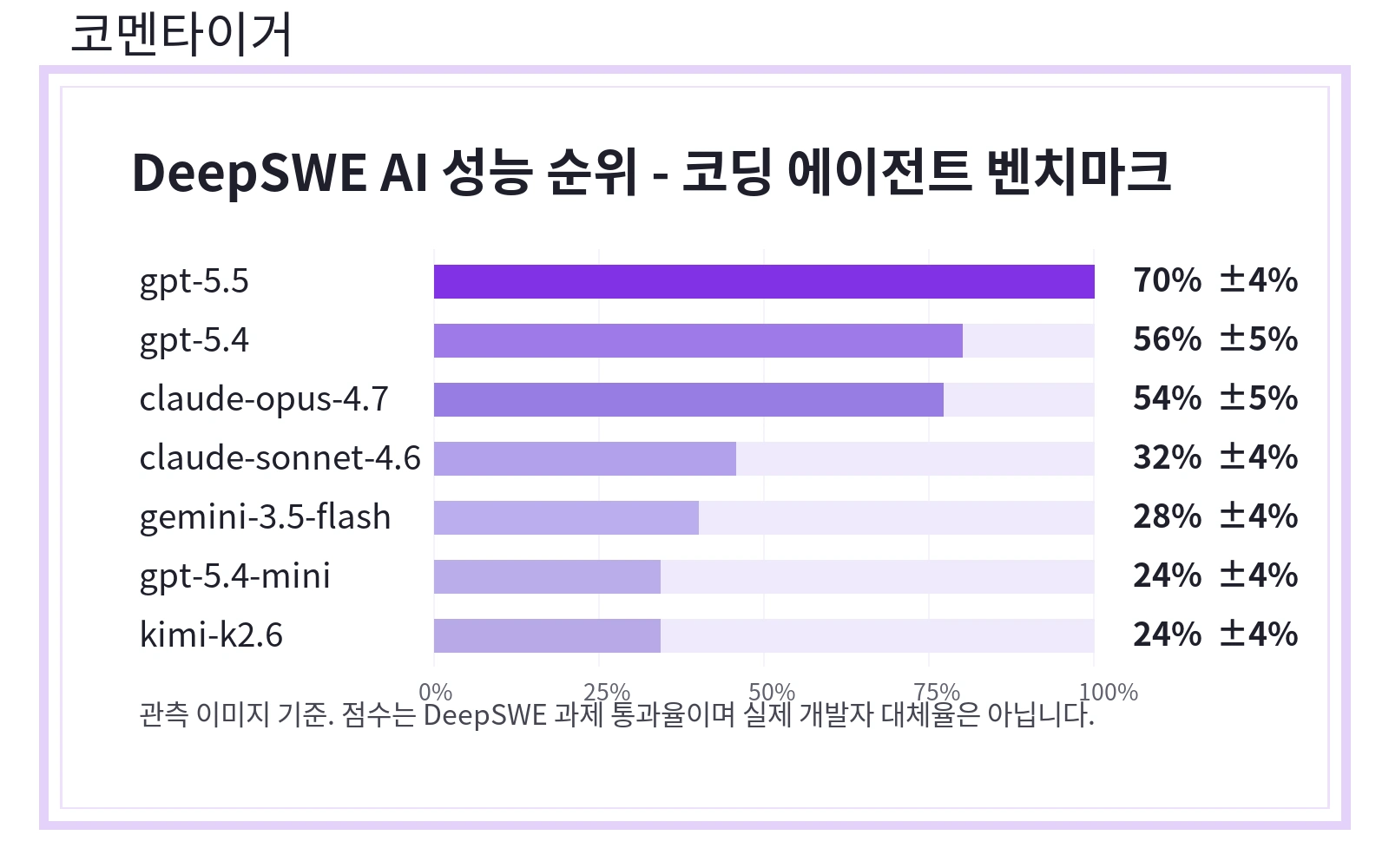
눈에 먼저 들어오는 건 GPT-5.5의 70%입니다. 2위권인 GPT-5.4, Claude Opus 4.7과도 꽤 차이가 납니다. 다만 이 숫자를 절대적인 “개발자 대체율”처럼 읽으면 안 됩니다. DeepSWE는 특정 조건, 특정 에이전트 구성, 특정 과제 묶음에서의 통과율입니다. 실제 업무에서는 저장소 구조, 테스트 품질, 권한, 외부 API, 코드 리뷰 기준에 따라 체감 성능이 크게 달라집니다.
그럼에도 이 표가 흥미로운 이유는 상위 모델 사이의 차이를 꽤 선명하게 벌려 보여준다는 점입니다. 기존 코딩 벤치마크가 포화되면 최고권 모델들이 비슷한 점수대에 몰리는데, DeepSWE는 더 긴 작업으로 변별력을 만들려는 시도입니다.
왜 기존 코딩 벤치마크만으로는 부족했나?
코딩 AI 평가는 생각보다 쉽게 오염됩니다. 유명한 문제, 공개된 PR, GitHub 이슈, 과거 풀이가 학습 데이터에 들어갔다면 모델은 문제를 “해결”한 것이 아니라 사실상 기억했을 가능성이 생깁니다. 또 짧은 문제는 모델의 순간적인 코드 생성 능력은 보여줘도, 긴 작업을 유지하는 능력은 잘 보여주지 못합니다.
DeepSWE가 내세우는 차별점은 이 지점입니다. 공식 페이지는 과제를 기존 커밋이나 PR에서 가져온 것이 아니라 새로 작성했다고 설명합니다. 또 91개 저장소와 5개 언어에 걸친 다양성, 실제 동작을 검증하는 hand-written verifier를 강조합니다.
이 대목은 꽤 중요합니다. 코딩 에이전트는 이제 “코드 한 덩어리를 잘 쓰는가”보다 “낯선 프로젝트에 들어가서 요구사항을 해석하고, 필요한 파일을 찾고, 수정하고, 검증하고, 실패하면 다시 고치는가”가 더 중요해졌습니다. 실제 개발에 가까운 평가는 당연히 더 불편하고, 더 비싸고, 더 시간이 걸립니다. 대신 얻는 신호는 훨씬 실전적입니다.
DeepSWE가 보여주는 코딩 AI 경쟁의 방향
이번 표에서 느껴지는 가장 큰 변화는 “모델 성능”과 “에이전트 성능”이 점점 분리되고 있다는 점입니다. 같은 모델이라도 어떤 실행 도구를 붙이는지, 어느 정도로 탐색을 허용하는지, 테스트를 어떻게 돌리는지, 실패 후 재시도 루프가 얼마나 좋은지에 따라 결과가 크게 달라집니다.
DeepSWE README도 Pier, mini-swe-agent, Claude Code, Codex, Gemini CLI, OpenCode 같은 실행 방식과 에이전트 구성을 언급합니다. 이제 코딩 AI 평가는 “어느 모델이 똑똑한가”에서 끝나지 않습니다. 실제로는 모델, 도구 사용, 샌드박스, 테스트, 파일 편집, 로그 해석이 합쳐진 시스템 싸움에 가깝습니다.
이 순위표를 볼 때 주의할 점
- 리더보드는 계속 바뀔 수 있습니다. 이 글의 수치는 2026년 5월 27일 확인한 화면과 공식 페이지 기준입니다.
- 점수 옆의 ± 범위도 같이 봐야 합니다. 인접한 모델은 통계적으로 겹쳐 보일 수 있습니다.
- 실제 개발 생산성은 벤치마크 점수뿐 아니라 비용, 속도, 컨텍스트 길이, 도구 연동, 보안 정책에 영향을 받습니다.
- 벤치마크 과제가 공개되면 시간이 지나며 다시 오염 가능성이 생깁니다. 그래서 이런 평가는 지속적인 갱신이 중요합니다.
결론
DeepSWE 이미지는 단순한 AI 모델 순위표라기보다, 코딩 에이전트 평가의 기준이 바뀌고 있다는 신호로 보입니다. 앞으로 중요한 건 짧은 알고리즘 문제를 맞히는 능력보다, 실제 저장소에서 길고 지저분한 변경을 끝까지 완수하는 능력입니다.
첨부 이미지 기준으로는 GPT-5.5가 확실히 눈에 띄는 선두입니다. 다만 더 흥미로운 부분은 특정 모델의 1등 여부보다, 이제 AI 코딩 경쟁이 “코드 생성”에서 “소프트웨어 엔지니어링 작업 수행”으로 옮겨가고 있다는 점입니다. 이 흐름은 개발자 입장에서도 꽤 현실적인 변화입니다. 앞으로는 모델 이름만 볼 게 아니라, 어떤 에이전트 환경에서 어떤 종류의 작업을 얼마나 안정적으로 끝냈는지를 같이 봐야 합니다.
자주 묻는 질문
DeepSWE는 SWE-bench와 같은 건가요?
같은 계열의 소프트웨어 엔지니어링 평가로 볼 수 있지만, DeepSWE는 새로 작성한 장기 과제와 오염 방지, 프로그램 기반 검증을 강조합니다. SWE-bench류 벤치마크가 보여준 방향을 더 긴 작업과 변별력 중심으로 밀어붙인 시도에 가깝습니다.
GPT-5.5가 70%라면 실제 개발 업무도 70% 자동화된다는 뜻인가요?
그렇게 해석하면 안 됩니다. 벤치마크 점수는 정해진 과제 환경에서의 통과율입니다. 실제 업무 자동화율은 프로젝트의 복잡도, 테스트 품질, 코드 리뷰, 보안 제한, 요구사항의 모호함에 따라 달라집니다.
코딩 에이전트 평가에서 가장 중요한 기준은 무엇인가요?
단순 코드 작성 능력보다 문제 이해, 저장소 탐색, 다중 파일 수정, 테스트 실행, 실패 원인 분석, 재시도 능력이 중요해지고 있습니다. DeepSWE 같은 장기 과제 벤치마크가 주목받는 이유도 여기에 있습니다.